
How Apache Spark Support Drives Big Data Success and Powers Business Growth
Big Data
5 MIN READ
February 18, 2025
![]()

Big data has truly reshaped most industries, enabling businesses to extract valuable insights and drive precise decisions. This calls for robust tools and expert support. That’s where Apache Spark comes in, a fully open-source unified analytics engine designed for high-speed data processing and advanced analytics.
While its capabilities are vast, maximizing its value often hinges on leveraging professional Apache Spark support. This support offers businesses significant advantages, including optimized performance, tailored solutions, and streamlined operations, which are key to thriving in the data-driven era.
With over a decade of proven impact, Apache Spark has cemented itself as a cornerstone for big data solutions. However, its full benefits, such as real-time analytics, machine learning integration, and cost efficiency, require more than just adoption.
This blog explores why Apache Spark support is a trusted ally for attaining big data success and how it lets businesses stay ahead in competitive markets.
What Makes Apache Spark the Big Data Leader?
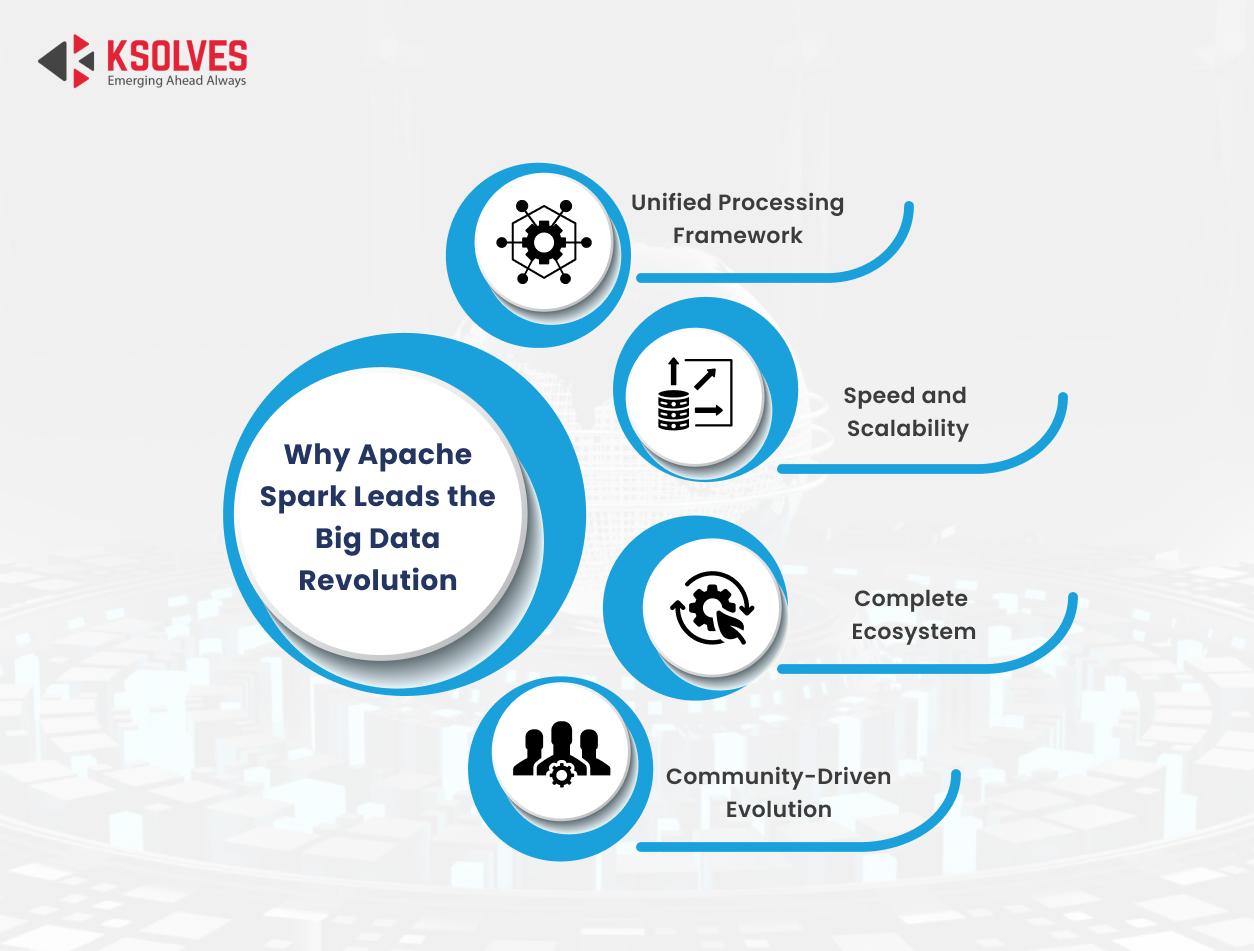
Apache Spark stands out as a leader in big data analytics for several reasons:
- Unified Processing Framework: Apache Spark supports Java, Scala, Python, and R and integrates with tools like Hadoop, Kafka (via Structured Streaming), and Cassandra (via Spark-Cassandra Connector).
- Speed and Scalability: Apache Spark’s in-memory computation can process big data up to 100x faster than traditional frameworks like MapReduce. This makes it a perfect solution for companies that deal with real-time analytics and time-sensitive operations.
- Complete Ecosystem: Spark comes with components like Spark SQL for structured data, MLlib for machine learning, GraphX for graph processing, Spark Streaming for real-time data streams, and Delta Lake for ACID-compliant transactions in big data environments.
- Community-Driven Evolution: Spark is open source, thus relying on the large community of developers worldwide who are enhancing the features and continuously working towards challenges, thereby ensuring that it is up-to-date and robust.
These features make Apache Spark an essential tool for businesses looking to derive actionable insights from their data.
The Role of Apache Spark Support in Big Data Success
Implementing Apache Spark without expert guidance can lead to challenges such as misconfigurations, suboptimal performance, and missed opportunities for innovation. Professional Apache Spark support bridges these gaps, offering:
- Performance Optimization: Expert support fine-tunes Spark environments through techniques like Adaptive Query Execution (AQE), optimized joins, and memory tuning.
- Scalable Solutions: As businesses grow, their data management needs expand. Apache Spark support ensures seamless scalability, adapting infrastructure to handle increasing workloads.
- Custom Implementations: Support teams tailor Spark’s functionalities to align with unique business objectives, integrating custom workflows and optimizing compatibility with existing systems.
- Troubleshooting and Maintenance: Quick response to technical problems reduces downtime, while proactive maintenance keeps the systems secure and updated.
- Training and Knowledge Sharing: The support providers offer knowledge transfer to internal teams, enabling organizations to independently leverage Spark’s full capabilities over time.
Benefits of Apache Spark Support Consultancy for Businesses

The advantages of supporting Apache Spark aren’t only technical ones that lead to strategic decision-making or operational efficiency. The main advantages are:
1. Higher Operational Efficiency
Professional support eliminates resource waste by optimizing Spark’s performance, minimizing job execution times, and improving overall productivity. With such efficiency, businesses can focus on strategic goals rather than technical bottlenecks.
2. Cost Management
The use of experts minimizes infrastructure costs, as organizations avoid unnecessary infrastructure costs. Such support teams further help identify cost-effective cloud or on-premise solutions for deploying Spark.
3. Better Data Integrity
Apache Spark support ensures data accuracy and integrity through robust pipeline design and continuous monitoring. Reliable data forms the backbone of effective analytics and decision-making.
4. Accelerated Innovation
Through support services, businesses can accelerate the deployment of advanced analytics capabilities such as predictive modeling and AI integration. This accelerates innovation and a competitive edge in their industries.
5. Strategic Insights
Support teams unlock the full potential within organizational data through proper alignment of Spark’s functionalities with business objectives. This means better forecasting, analysis of customer behavior, and market trends.
Real-World Applications: Apache Spark in Action
1. Retail and E-commerce
Retailers use Spark for real-time inventory management, personalized customer recommendations, and an optimized supply chain. Support services ensure that such applications run smoothly, bringing more sales and improving customer satisfaction.
2. Healthcare
In healthcare, Apache Spark processes huge volumes of data for patient records, predictive diagnostics, and drug discovery. It gets expert support to ensure compliance with the industry regulations and give better data security.
3. Finance
Financial institutions use Spark for fraud detection, risk analysis, and algorithmic trading. The service providers optimize these applications in terms of performance and reliability.
4. Manufacturing
Spark enables predictive maintenance and IoT data analysis in manufacturing. Professional support ensures that these systems scale effectively, reduce downtime, and increase efficiency.
Selecting the Right Apache Spark Support Partner
To fully take advantage of Apache Spark support, selecting the right partner is important. Key considerations include:
- Experience and Expertise: Look for partners with proven expertise in Apache Spark and a track record of successful implementations.
- Customizable Services: Ensure the support provider offers tailored solutions to meet your unique business needs.
- 24/7 Availability: Downtime can be costly, so opt for a partner offering round-the-clock support to address issues promptly.
- Scalability: Your support partner should be equipped to handle your business’s growth, ensuring seamless scalability and adaptability.
Conclusion
Apache Spark is very powerful in dealing with big data analytics, but it should be experienced professionally to thrive. From optimizing performance to making innovation possible, professional Apache Spark support benefits businesses irrespective of their verticals by properly using a company’s most valuable resource-full data.
Ksolves, with 15+ years of experience in big data and Expert Apache Kafka Support services, is now ready to meet the needs of implementing your projects smoothly. Our fully packaged support services mean that your projects have the perfect chance for a seamless, tailored Spark implementation. Ready to unlock the true power of Apache Spark? Start your journey towards big data success today. Let’s talk.
![]()





AUTHOR
Big Data
Anil Kushwaha, Technology Head at Ksolves, is an expert in Big Data and AI/ML. With over 11 years at Ksolves, he has been pivotal in driving innovative, high-volume data solutions with technologies like Nifi, Cassandra, Spark, Hadoop, etc. Passionate about advancing tech, he ensures smooth data warehousing for client success through tailored, cutting-edge strategies.
Share with